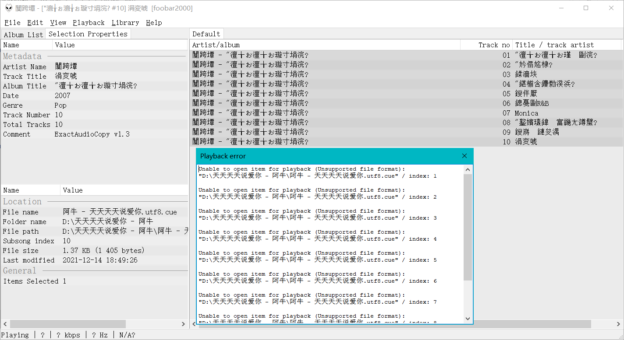
Exact Audio Copy(EAC)是一款在Windows下很常用的扒CD软件。在扒取整轨的时候EAC会生成对应的cue文件以便读取,但是如果你——作为一个Windows用户——从网上下载过使用其他语言版本的操作系统的用户——比如日本人——抓取的音频文件,你可能会发现自己的播放器有时会出现元数据乱码,甚至无法打开cue文件。
(以自己淘的阿牛的碟子为例)
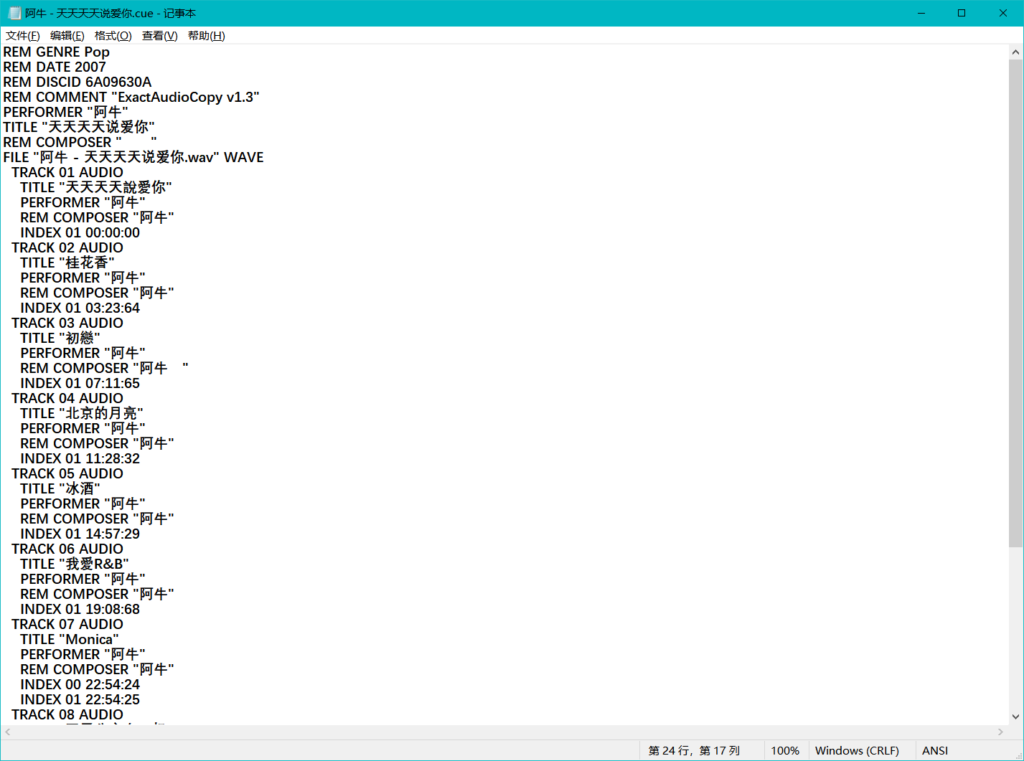
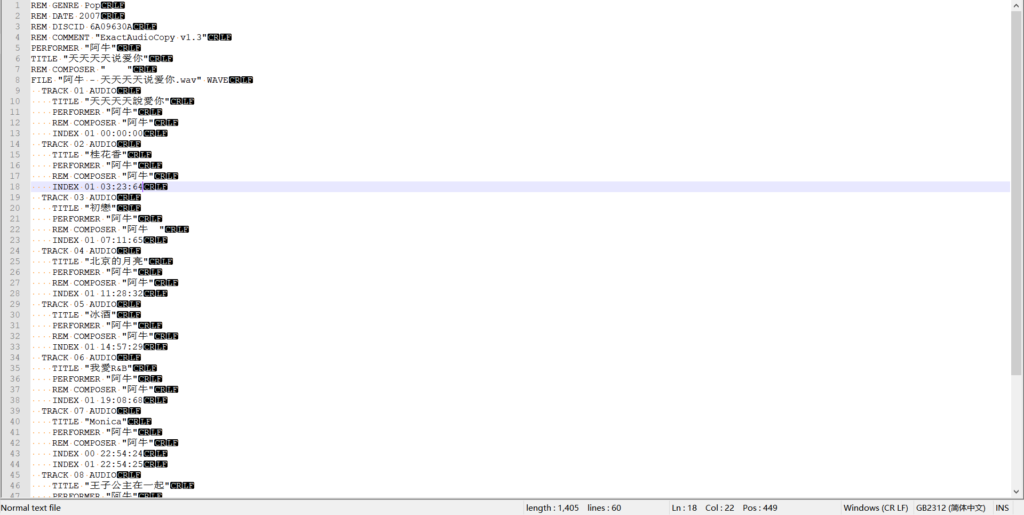


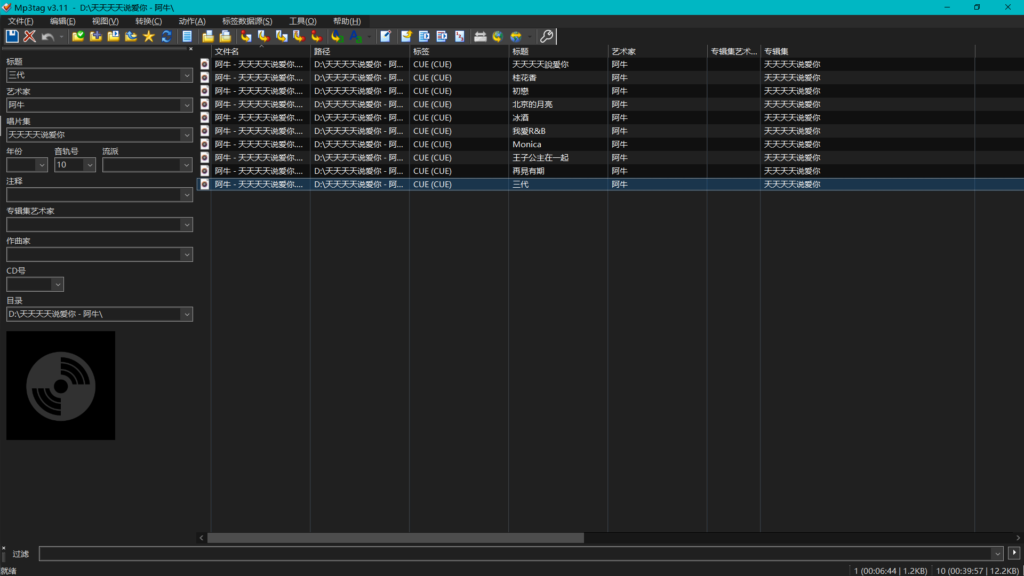
这是因为EAC的cue文件的编码是ANSI,虽然ANSI名义上是美国标准化协会的编码,但是实际上ANSI在Windows下的实现是根据Windows的语言而定的。在不同的语言下,不同的国家标准化组织为自己的语言制定了不同的编码标准。我的理解是,ANSI不一定遵循美国的标准,它代表的是在不同的语言环境下遵循对应国家的标准,正好有一个ANSI可以用,就直接拿来用了。而这个名称对于开发者来说,好处在于不必单独指定编码,交给Windows接口处理就可以。
因此,如果你是简中Windows用户,你的cue编码显示的是ANSI,但实际上是GB2312等GB编码;如果是日语Windows用户,实际上是Shift-JIS编码。
你可能会说,UTF-8不是很好吗?可以支持不同国家的编码。
那么我们用notepad++把编码转成UTF-8试试?
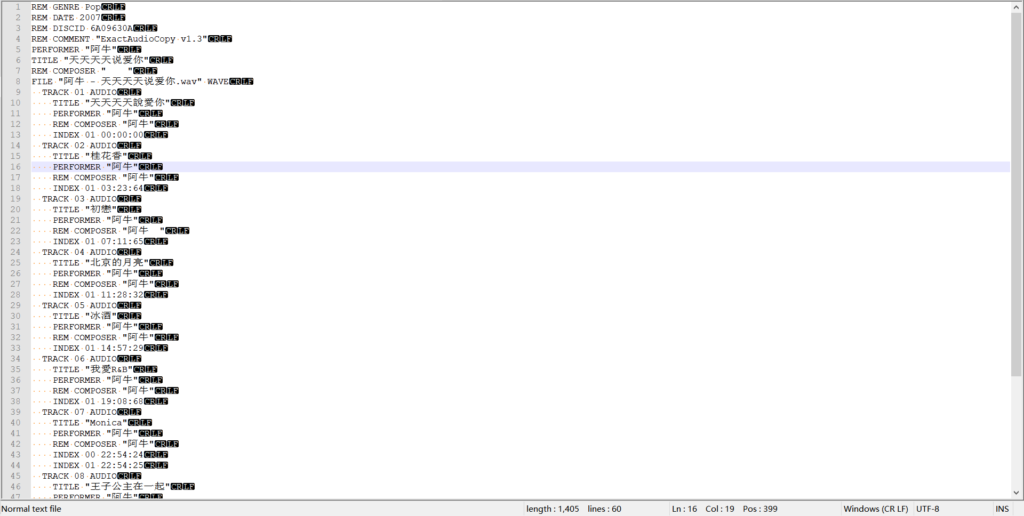
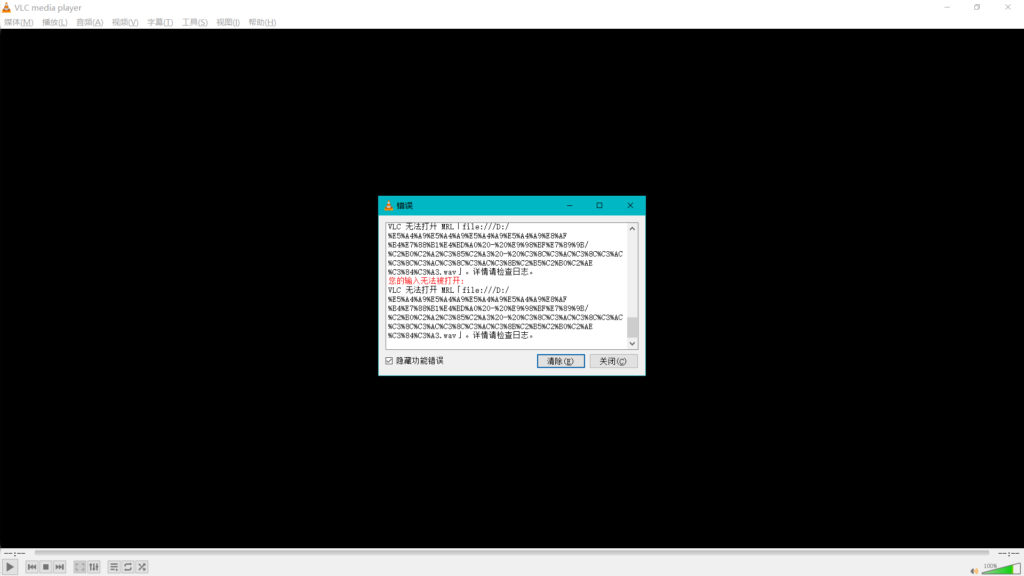
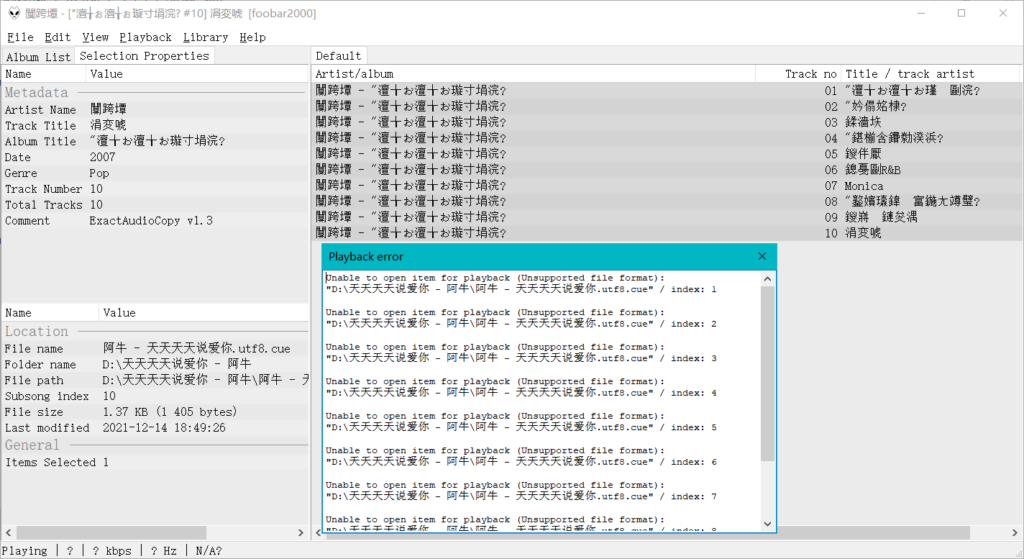
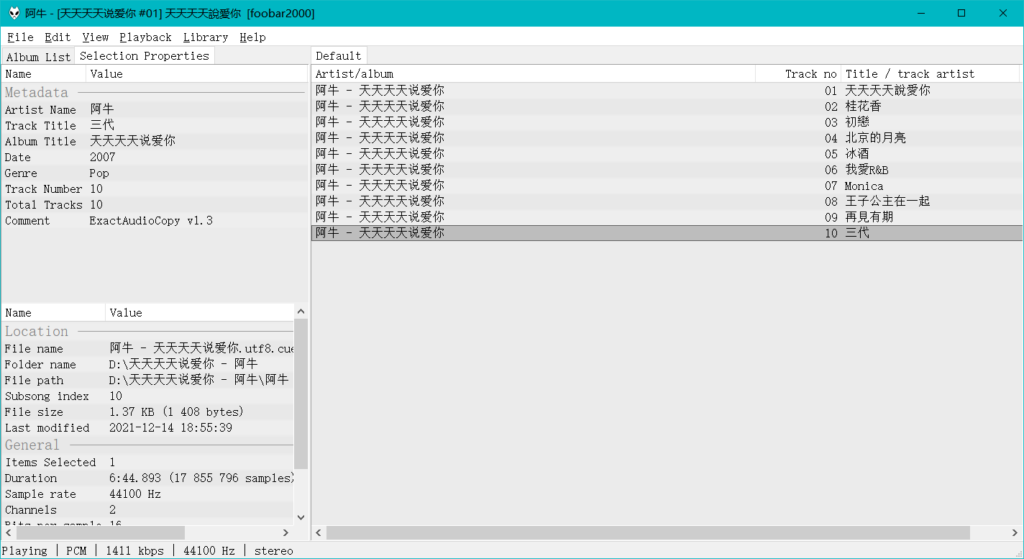
你这时候会发现用Foobar2000和mp3tag打开变成乱码了……变成乱码了……甚至还打不开文件……
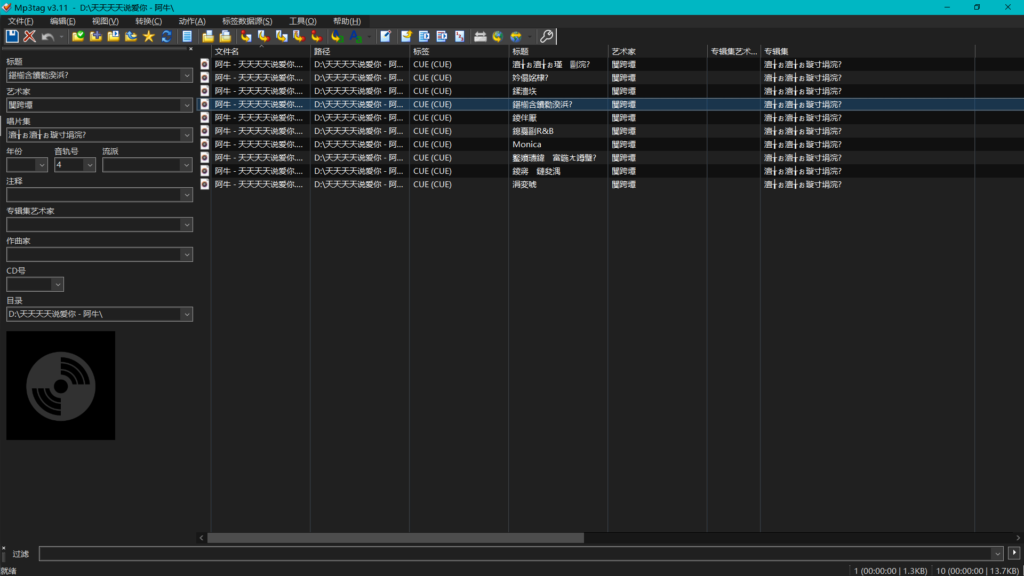
正确的操作方式是加上BOM,可以再用npp转为带BOM的UTF-8:
所以我想建议,想体验自己扒碟的人,在扒完之后不要就以为万事大吉了,你还有编码的事情要处理~
当然你其实可以把自己系统的区域设置改成英美,勾上支持UTF-8,但是要面对日常的乱码……
所以这样就完事了?不,我还要再批判一番BOM。
看到上面的Foobar2000在没有BOM的时候的表现了吗?
Windows下的Foobar2000只能打开带BOM的cue文件,同样地,Mp3tag也只支持打开带BOM的的cue文件。即使你在上面开了UTF-8支持,EAC输出的也只会是带BOM的UTF-8 cue文件……
虽然这样做在Windows下没什么问题,但是如果你的文件传到了其他系统的话,就可能会出现问题……而且从网上下载的文件即使自称是UTF-8,因为没有BOM,就可能读不出来……
但是,尽管如此,带BOM的UTF-8仍可能是跨平台性最好的编码。Linux下可以较方便地进行转换,识别也方便。尤其是大多数下载者都还在用Windows的情况下……而且Linux上能和Foobar2000、EAC、Mp3tag打的开源替代太不出名了……
而且这里似乎还可得出另外的结论,尽管 Foobar2000、EAC、Mp3tag很好用,但是它们在字符处理上更愿意用Windows现成的轮子,而不是在软件里提供编码选项。虽然它们在自己的领域很强,但在其他的细节上的处理可能过于保守……与开源社区的理念相悖。
为什么我会关注这个问题?因为最近试着用mp3splt批量给手上的整轨文件分轨,在这上面吃了点苦头……
综上所述,扒碟以后请再麻烦一下,把cue文件转为UTF-8 BOM,用FixCue也好,用记事本也好,举手之劳。
(水文结束)
本文以 Creative Commons 4.0 International 发布,允许商业使用。